Some Equipment

I had a chance to play one piece at a concert. Can you guess what I chose to play? People like to hear the pieces they know, yet they expect some novelty. So I played my special more jazzy version of The Entertainer. It's a great idea: you start from a fragment of the standard version of the piece, then you re-phrase it to your way to show the difference and repeat this with the next fragment, gradually playing less and less the standard version and more and more your version. Many artists use the trick and the audience always like it.
My impression from playing the Scolemowi Klawer: the sound is enormously powerful with huge dynamic range, yet the keyboard is very sensitive and responsive. More sensitive, more responsive and require less power than a typical grand piano keyboard, so you have to get accustomed.


Music from the AI Scientist's Perspective
This page is still under construction, but I decided to publish the work in progress and update it every time I add something new.
Introduction.
Music as popular human activities are the field of studies of many scientists from various domains. As I am not an anthropologist, neither psychologist, I will not write here about the origin of dance and music, neither about their purpose and influence on people. My area of interest is AI and IT, so I will write how our experience with dancing and music can be improved with artificial intelligence. However, I will start here with some mathematical description of music, as probably not everyone who reads this is familiar with that and I will need these concepts later.
Problems with Scales and Frequencies
In western culture only few artists use microtonal scales or scales other than the 12-step semitonal ones and these rarely used scales will not be considered here.
The well sounding consonant intervals are expressed by the ratio of two small natural numbers. Such scales were used from the oldest times in various versions, the best known being first the pythagorean tuning and then just intonation. It is relatively easy to tune the instrument by ear in just intonation scale using the intervals like the perfect fifth with frequency ratio 3:2 or major third (5:4), etc., because the effect of the sound waves meeting at zero at their every multiple is easily detectable, but this clear intervals do not occur at the equal tempered scale. Thus these scales (for the sake of simplicity I call them all "just intonation") sounded perfectly, but only for a limited number of sound combinations. In the baroque era some people tried to sacrify some of the purity for the sake of universality and developed several versions of the so called well-tempered scale, which differed by the degree of preferences given to sound purity vs universality. Bach was famost for writing his compositions in every key of the well-tempered scales to show the differences between the keys. He must be very unhappy and disgusted when he looks down from heaven as many pianists today distort his ideas by playing his compositions in the equal temperament. First, all the keys sound the same in equal temperament. Second, the equal tempered scale divides the octave into 12 equal intervals, so it can be considered the extreme of the well-tempered scale with the balance: universality=100%, sound purity=0%, while the Bach's well temperament in approximation used the balance of universality=33% and sound purity=67%. The equal tempered tuning was known for centuries, but its impurity was unacceptable to people of that times, so it was not used. But later something strange happened: in spite that the sound of equal temperament was inferior to that of well temperament, the ease of use took precedence over the quality and it gained on popularity in the late 19th century and gradually became the dominant tuning of pianos. Of course no-one was able to tune any instrument to that scale, before electronic detectors of sound frequency were invented, for that simple reason that assessing by ear the interval of the twelfth root of two: 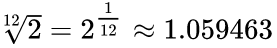 or any its multiple is out of human capabilities. So all the pianos tuned by ear to the equal tempered scale were really more or less out-of-tune (including my old accoustic piano, which you will be able to hear and see the frequency measurements in the video). Here's a great source of information on tunings and scales.
or any its multiple is out of human capabilities. So all the pianos tuned by ear to the equal tempered scale were really more or less out-of-tune (including my old accoustic piano, which you will be able to hear and see the frequency measurements in the video). Here's a great source of information on tunings and scales.
Nowadays, when we have digital pianos and keyboards, dynamic scales are the way to go and the equal tempered scale is a relic of the past, that from unknown reasons is still the most popular scale in western culture. (The just intonation scale and its variants are also popular, but on the second place, mostly for fretless string instruments and for vocals without a piano, and of course for digital and software instruments. All other scales are nowadays used very seldom.) Well, maybe the reasons are known: the inertia of people and their unwillingness to get rid of the relics of the past, when the technology development allows for this. But such reasons are not justified. Other impractical relics and remains of the past are also in broad usage, as first of all the official paper correspondence and paper documents inside the organizations, then the organization of learning in elementary and high schools (many aspects, a topic for a dedicated web page), next the qwerty keyboard layout, next the mp3 and jpg formats and many many others. These are the examples that can be changed without any invenstment, only good human will is required.
Anyway coming back to the scales. The pitch difference of one semitone on the equal tempered scale is 5.95%. The pitch difference between two sounds that a human ear can detect is approximately 0.3% in the central frequency range 200Hz-2kHz, that is about 1/20 of the semitone. However, if two sounds co-exist even a smaller difference is detectable due to the overtone interferences. A perfect (12-step) musical scale does not exist, as this is mathematically impossible. However, the question is how close we can get to the perfectness. Definifely we can get much closer with dynamic scales than with static ones. For instance the standardized frequency of a' is 440 Hz (though some believe that 432 Hz is a better choice). But the frequency of every other sound can depend on the context - on which notes were played before or are being played together with it. This is a so called dynamic scale. It was never a problem to use dynamic scales on instruments such as a violin, but in the prehistoric times, before we could connect keyboard instruments to a computer it was pretty hard to obtain a dynamic scale on them (there were some experiments with three differently tuned grand pianos, which worked as a single instrument or with instruments with more than 12 keys per octave, but these were not perfect solutions). However, nowadays it is pretty easy and the limitation no longer exists! That is why we can and should use the dynamic just intonation scale (the most obvious choice) and other dynamic scales also while playing keyboards, electric pianos and electric guitars. Well, some artists do this. But especially in popular music no-one bothers.
In this video I explain the dynamic scales and both dynamic ranges. Software used in the presentation: Audacity and Just Intonation. For a better comparison, I played the same piece in 2020 as in 1993. Equipment used for the 2020 recording: keyboard Yamaha DGX 630 connected to an audio interface Steinberg UR242, software: Reaper. For the 1993 recording: an acoustic upright piano recorded on a TDK A/90 cassete (type I) using Unitra ZRK M9100 cassette deck and Unitra Tonsil MD249 stereo microphone, digitalized on Onkyo TA-RW cassette deck with Steinberg UR242. It was recorded with Dolby-B, but for the digitalization I switched Dolby-B off, as the noise could be better (more selectively) reduced in Audacity. A question: which recording sounds better? The answer is not obvious: the 2020 recording is perfectly clear, the 1993 recording has high noise floor (even after de-noising), but is more realistic. Obviously you can't merge them in Reaper or in another DAW to join their advantages. Applying AI to merge their advantages can probably be performed. Although I am not aware of such applications I have an (still unverified) idea how to do it.
Problems with Dynamic Range
First of all, we must clarify that two different concepts can be understood under the term "dynamic range": 1. the difference between the minimum and maximum sound level (which is also called signal-to-noise ratio SNR and is responsible for the levels of details), 2. the difference between the average and the maximum sound level, which is also called DR, and in this case high DR (18dB or more, depending on music genre) is the main determinant of a recording quality. High DR means low distortions and the feeling of life, breath and power in music. In the first concept the greater means the better. Always. Even if it is outside of the resolution and range of DACs and human ear, which are both about 20 bits or 120 dB under very good conditions (20 dB ambient noise and the typical under-noise-level audibility of 15 dB. Yes, it's about 15 dB, not 0 dB, as many "experts" claim. Also the minimum noticeable difference in sound levels is much smaller than the hearing threshold, not equal as the same "experts" claim.). Thus, the extra bits (21-24) enable effective manipulation of the sound files without causing audible artefacts. In the second concept (average-to-maximum) also the greater dynamic range is better, but up to a certain limit, which is set by the dynamic range of live performance after compensation of the performance imperfections, which depending on the music genre, can be typically in the range of about 18-30 dB. The minimum-to-maximum range is limited by the media capability, recording equipment and sound engineer's qualifications. The average-to-maximum range is limited mostly by the sound and mastering engineers' qualifications. Moreover, the average-to-maximum range can be divided into the micro dynamic range (the average-to-maximum range when the band plays at constant volume level) and the macro dynamic range (difference in sound level between the quiet and the loud parts of the piece). High micro range ensures high recording quality (no cut-off transients, no distortions, good instrument separation, etc.). The optimal macro range is more subjective, as it is significantly influenced by the artistic interpretation. For example if we use the presented below song "On the Sunny Side of the Street" for listening, we want both ranges to be high (the upper part of the figure). If we use the song for dancing at the party, we want the micro range to be high, but could prefer smaller macro range (the lower part of the figure). Yes, in this way the song loses some beauty and expressive power, but is more suitable for dancing in a noisy room (people at the party make the noise). But we never ever should compress the micro dynamic range, as it will not help for the outer noise and will reduce dramatically the quality of the music. That is what some poor sound engineers don't know. And then we must struggle to try to correct their work.
The common problem we deal with many recordings is that both dynamic ranges are too small for the music to sound well and/or to allow some types of post-processing. However, music with 65 dB minimum-to-maximum dynamic range and 20 dB average-to-maximum dynamic range sounds way better than music with 120 db minimum-to-maximum and 10 or 12 dB average-to-maximum; in other words: the skills of the sound engineer are more important than the available technology, and yes a lot of well recorded and well mastered music from the 1960s sounds better than lots of contemporary popular productions, where no-one cares. Of coure where someone cares today the results are much better than when someone cared in the 1960s. So far where the average-to-maximum range in some music was below DR12 I used to delete this piece as unrecoverable (unrecoverable by me, not by AI). When it was over 12 dB (DR12) I tried to extend this to about DR18 (my threshold of acceptance), with better or worse outcome. The main problems being reversing the multi-band compressors and regaining the cut hi-hat and drums transients (where I used mostly my experience to guess the settings and tried ICA - independent component analysis, to separate the sources). I will write more later and provide some sound samples to explain in detail these problems. But now AI comes here with help in extending both dynamic ranges and also fixing other problems. Although AI can't replace the need for good original sources, it can improve the bad sources making them sound closer to the good ones. (By the way is ICA not AI? Partially, but surely not the top level AI.).
So this is the first application of AI in music: dynamic adjustment of the sound pitch on keyboard instruments and on electric guitars with frets. To explain this concept, below I provide some sound samples which I generated on the Yamaha DGX 630 keyboard connected to my laptop running the Just Intonation software with some modification I introduced into it. (Also some explanations can be found on their web page).
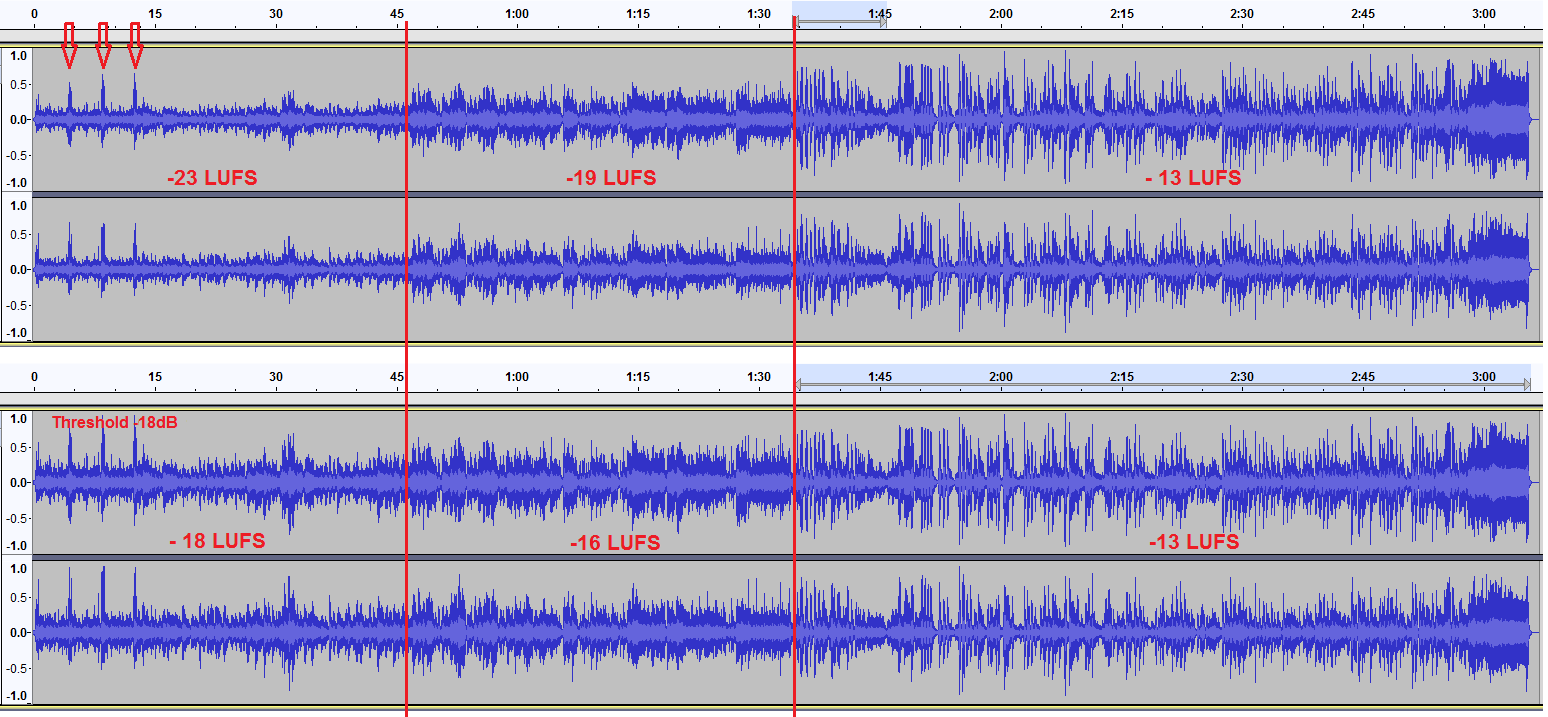
On the Sunny Side of the Street from Så Ska Det Låta by Ballroom Big Band
En example of adjusting a song for dancing in a noisy environment.
We should change only the macro dynamic range by amplification.
The micro dynamic range should stay intact.
Problems with Old and New Media Digitalization, Noise and Music Restoration
The biggest problem with the minimum-to-maximum dynamic range, which we can also call "resolution", is when it falls below 70 dB - then the lack of details and/or noise becomes, well... more than obvious. As a matter of fact the best vinyls approach 70 dB and most have lower dynamic range and today we can hear the lack of details on vinyls clearly in comparison to digital recordings. (I have a bad news for the fans of vinyls: even a correctly made 128kbps mp3 sounds much better than the best vinyls - the sound is more detailed and less distorted.) In the case of vinyl records we frequently have access to the master tapes or even digital sources from the 1980s, which ensure much better quality and broader dynamic range. But what if the master tapes don't exist? Then always something called artificial intelligence exists. There are lots of great pieces available only on shellac records. Shellac records mean more problems: no master tapes, limited bandwidth, high noise floor, wow and flutter, and frequently unknown equalization curve. Some of the restoration problems are similar to recovering the dynamic range of music compressed with a multi-band compressor with unknown settings. The noise and distortions are of a lesser concern (easier to fix), but the main difficulty here is that we need to restore a lot of information (bit depth), which simply does not exist on the original media. So how to generate the non-existing information to make the music sound as it was recorded with the technology we have in 2020? It is impossible with 100% accuracy and surely more difficult with the acoustically recorded music (before 1925). However, AI can allow here for very good results.
Now about the restoration of new music. Music carefully recorded in late 1960s sounds much better than a lot of the popular music recorded in 2010s. Why? Because they cared and had skills and knowledge, which in spite of having poorer technical possibilities resulted in better sound. Skills are more important than equipment. Not only in music, but in each area of our life. Now everyone has the technology, but only a few have the skills. The others thing that technology will do the job. But they are wrong. And the poorly recorded modern music also requires restoration. Not only restoration of dynamic range and removal of overly used effects, as artificial reverb, but also restoration of the sound resolution. Well, the resolution is definitely over 70 dB, but is far behing well recorded music and below current technical possiblities. I didn't attempt to measure the resolution yet, but I will try. Anyway, while listening on my Proac Response D25, the difference in resolution between well recorded and a lot of popular current music is evident not only for me, but also for everyone else who listens to this.
Problems with Sampling Frequency and Post-processing Operations in Frequency Domain
"There is a huge difference between mp3 and 24/192 uncompressed formats" - you can read in some sources. "There is literally no difference between mp3 and 24/192 uncompressed formats" - you can read in other sources. Of course both sources are supported by music samples, which prove that the author is right. Oh, yes we know this phenomenon from many domains of our life: people backing their thesis with tendentially selected sources. If you want to know my opinion, it is following: "we need 24/192 uncompressed formats, even if we can't hear any difference between them and mp3". Why? Because you can't do any (almost any) editing of the mp3 file without causing audible artefacts, and especially any editing in the frequency domain. Music that can't be edited is of a limited usability. The frequent problem is when we want to change the tempo of the music (without changing the pitch). It is useful for many reasons: for example we want this music for dance, but it is too fast. Or we want to mix two pieces in such a way that we need the same tempo of both. Another problem is when we want to change the pitch to make the music in-tune with our acoustic grand piano to play together with it. There are many reasons to change the music tempo, speed or pitch. Try to do it with mp3 - good luck! Wait a moment... But if I have only the mp3 source, can't I do it? With the classical algorithms no - the artefacts will be immediately apparent. Even with high resolution files we have limitations here. But this is the next place, where IA comes with help to solve this problem and to change my opinion to "High resolution uncompressed files are usefull but artificial intelligence can be much better here (and not only here)".
Maybe I should explain one more thing here: everything should be recorded at 24 bits and at as high sampling rate as possible. You may ask: why do I need a sampling rate of 192 kHz, as 44 or 48 kHz is enough to cover the audible spectrum. There are two reasons. The first one is noise reduction. Every doubling of recording frequency allows for decreasing the noise level about 3 db. Thus, the difference between recording at 44/48 kHz and 192 kHz is 6 dB lower noise! That is much! It roughly corresponds to using four microphones and then averaging their signal to remove the noise. It works in a similar way as making four photos of something and then averaging them to remove the noise. I will demonstrate here both: noise reduction in photos and in audio obtained in this way. In both cases the results are spectacular. The second reason is that some DAW plugins and some post processing operations work better at higher frequencies. Recording at 24 bit is also a good idea for two reasons, even if the final audio file will be 16-bit. The first reason is that you don't have to carefully balance between clipping and losing the lowest bits. You just set the recording level to any value low enough and you forget about it. The second reason is that the lowest bits are useful in the post processing, for instance, they can be made louder while still keeping high quality (in the same way as the RAW files in cameras are 12 or 14 bits, even if most monitors can display only 8-bits and a few 10-bits, but this allows for extracting details from shadows and for other operations). And finally you may say: "It was true in the old times, before we had the wonderful, omnipotent, all-problem-saving deep learning. Now we can record the whole concert on the microphone embedded in a smartphone and deep learning will not only incredibly improve the quality but will also replace the mastering engineers." Hopefully, such times will come soon, but as for now AI is not a replacement for good audio (or video) processing. AI is the way to improve the processing and the better data we provide to the AI system, the better results we get. The reconstruction process in all AI systems, including the wonderful, omnipotent, all-problem-saving deep learning is done by comparing the new data to the known samples and what we obtain as output is some guess, some approximation, which can be better or worse, depending besides the model on the training data and actual (test) data quality and the match between the training and test data.
How Artificial Intelligence Can Solve All these Problems and Improve the Music Quality
This example Using Deep Learning to Reconstruct High-Resolution Audio shows the idea of how the minimum-to-maximum dynamic range can be expanded. There are audio samples and the source code is available. However, good training data is a must. In the case of music restoration, gathering the proper data is a much bigger and more complex task than learning and optimizing the system (the audio samples in the linked article demonstrate voice restoration only).
A More Advanced Topic
In the issues considered so far we could define the expected outcome, thus we could create a training dataset consisting of the inputs (the music to correct) and the output (the corresponding pieces after correction). There were a lot of problems, but anyway we knew what we wanted to achieve. Now the problem is more difficult: we want IA to obtain good results, but we cannot define them clearly. The only definition we can provide is: "make it sound good" and we can formulate the objectives only in a very broad area by providing other good sounded pieces. Will it be enough for AI? Is deep learning a universal solution to all our problems, even if we can't define them clearly? Some believe it is.
The task is to adjust old music to modern ballroom dancing. There are lots of great dance music pieces from the past decades. Even the technical quality of many recordings is quite good. However, over the years the speed of some dances was gradually decreasing, and with current more complex dance technique we cannot use the old faster music. The biggest change is in rumba, where the tempo slowed down from 27 to 24 bars per minute (bpm). When we compare how the rumba was danced in 1970s and 1980s and how it is danced nowadays, we clearly see that it was a brilliant move to reduce the tempo. This made the dance more precise, more dynamic and more sexy by giving the woman time to fully show her beauty. If the music source is of a sufficient quality, we can frequently reduce the tempo (technically tempo and speed are different concepts) without too much distortion. But here comes another problem. The music was arranged to be played at 27 bpm not 24 bpm. At 24 bpm it loses its artistic character and beauty. That sometimes even happens with slow waltz after decreasing the tempo from the old 30 to the current 29 bpm. However, it depends on a particular case and some songs still sound good at the reduced tempo. In other cases what we really need is to re-arrange the pieces and record them once again at the new tempo. But, we don't have neither the composers nor the musicians to play it again. Everything we have is a computer and a rather vaguely defined objective. Can IA help us here? I am not aware of any well-working current solution, but for sure we can expect it in the nearest future.
Creative Commons (You are free to copy, share and adapt all articles and software from my web page for noncommercial purposes, provided that you attribute the work to me and place a link to my home page. What you build upon my works may be distributed only under the same or similar license and you may not distort the meaning of my original texts.). żółta oczojebna kurteczka